Return to Home
Dropbox Metadata
The smallest MVP that could answer the biggest retrieval question
The problem
By 2020, "I know it's in here, I just can't find it" was one of Dropbox's most consistent enterprise complaints. Folder hierarchies didn't scale with team growth, naming conventions broke down across collaborators, and without shared language, retrieval failed. Often, this sort of breakdown occurred at the moment it mattered most.
Why metadata?
Competitors had classification and tagging systems. The obvious move was feature parity. I pushed to reframe the opportunity: rather than replicating what existed elsewhere, we could let users define their own taxonomy. Teams already had unofficial organizational language. The question was whether we could surface it.
Reframing the research question
We started with a broad question:
Design approach
The space was huge, with options like key-value pairs, automated classification, and machine learning. To move quickly and learn, I scoped an MVP around tags.
Key design challenges we solved:
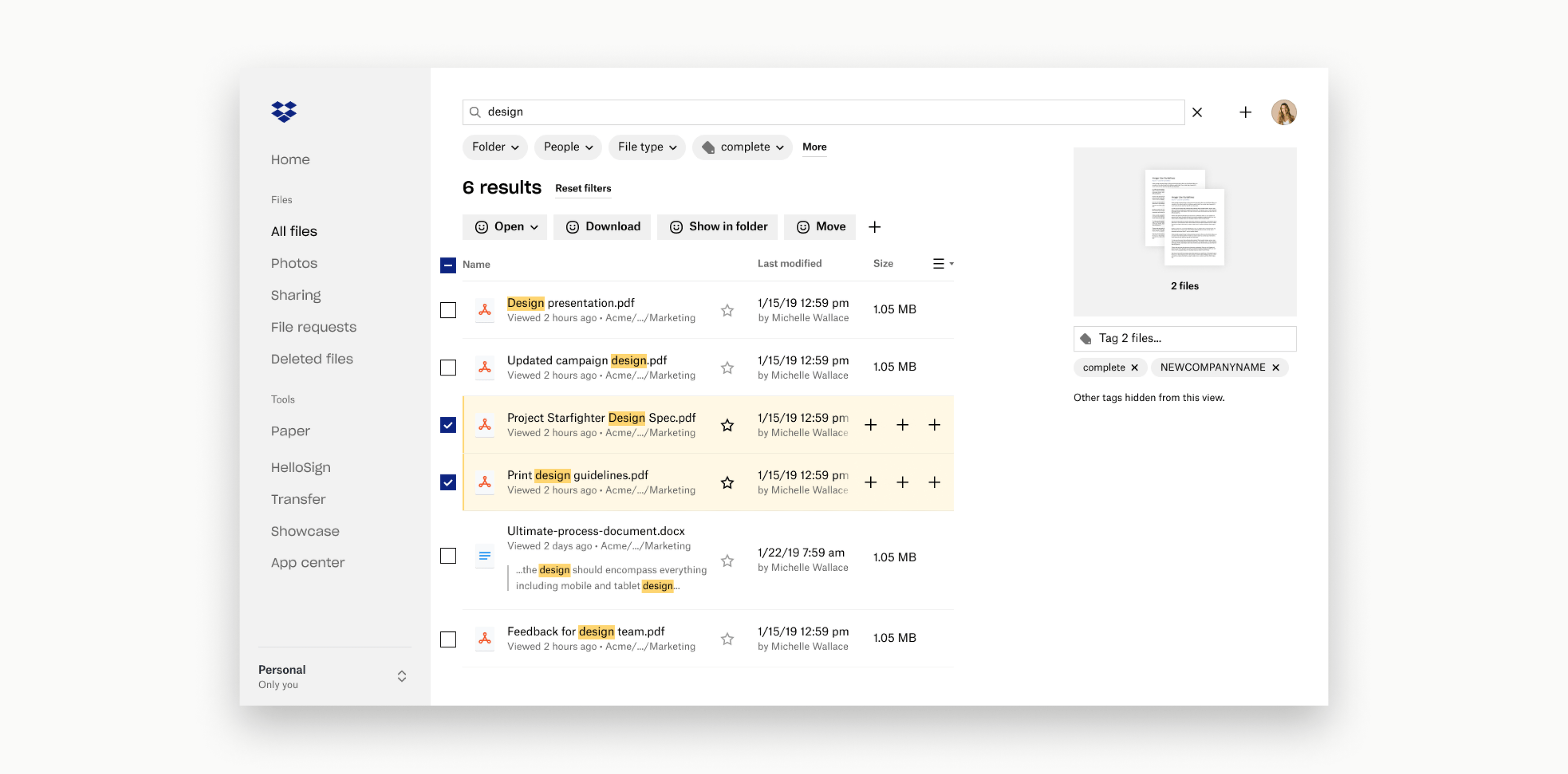
How should tags appear in search?
- Tags needed to be visible in both the search bar and results list.
- We had to make this work without breaking existing search interactions, so working closely with eng was critical.
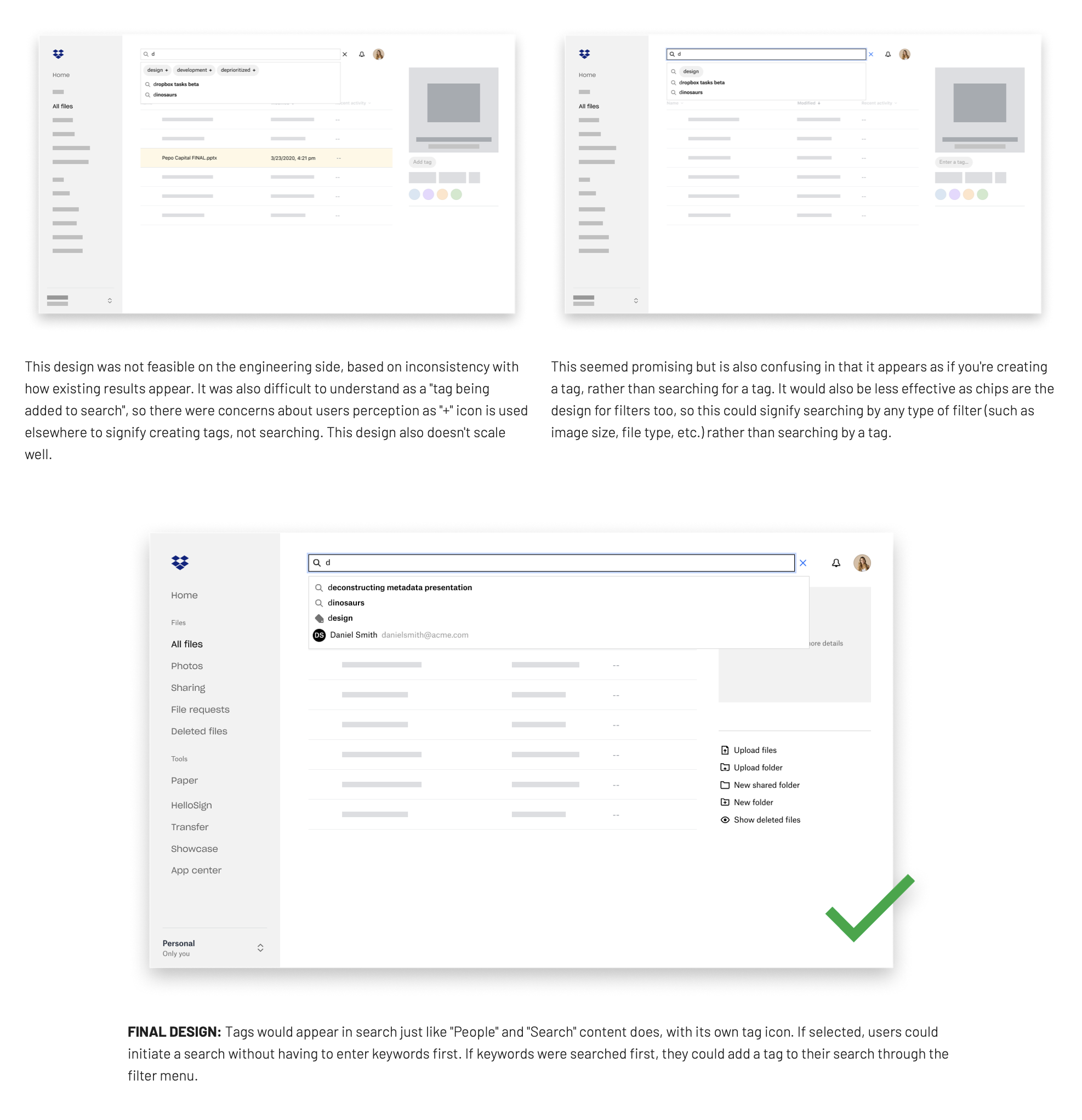
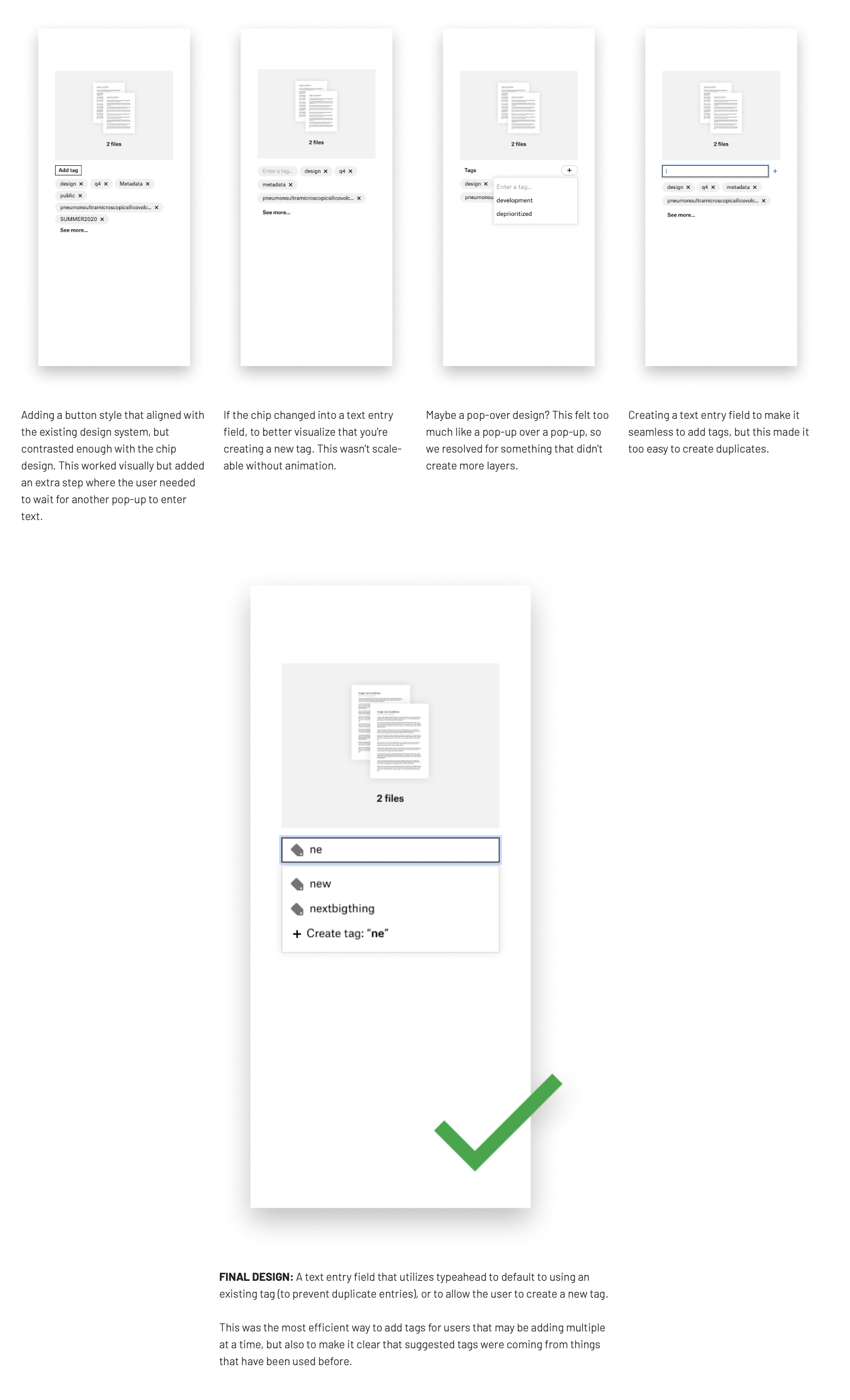
What’s the most efficient and identifiable way to add a tag?
Tagging is repetitive. A clunky interaction would mean abandonment. We explored multiple approaches to balance:
- Easy discoverability for new users.
- Low-friction speed for power users who tag regularly.
How should tagging fit into the design system?
There were no existing patterns for tagging in Dropbox. To avoid introducing one-off interactions, I worked with the design systems team to evolve existing patterns so tagging felt native across web and desktop.
The solution
I scoped the MVP to two core scenarios: applying tags to files and folders (in bulk and individually), and surfacing tags in search queries and results. This gave us enough surface area to measure real behavior while keeping scope tight enough to ship and learn. The foundation was intentionally minimal, designed in a way to inform the next layer of investment in smart collections, automated tagging, and rules-based views.
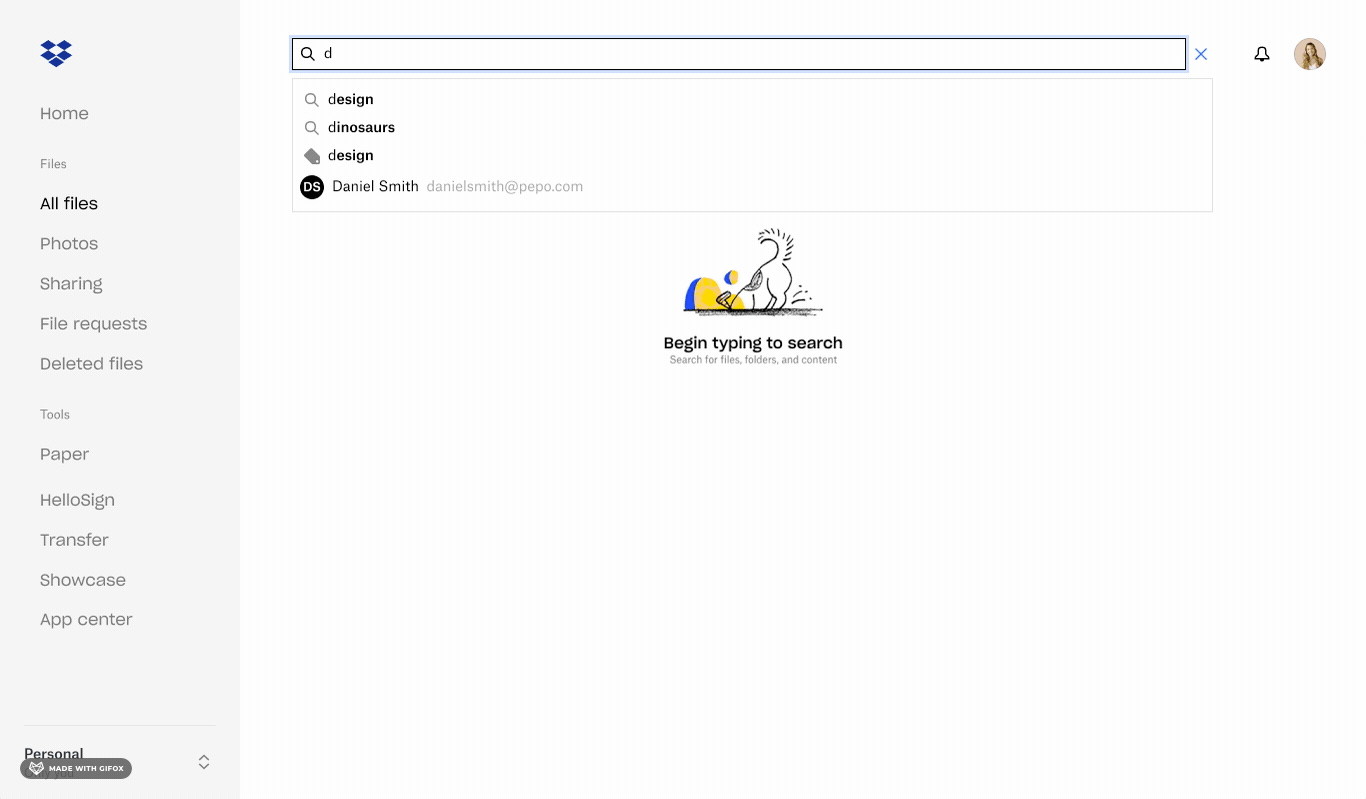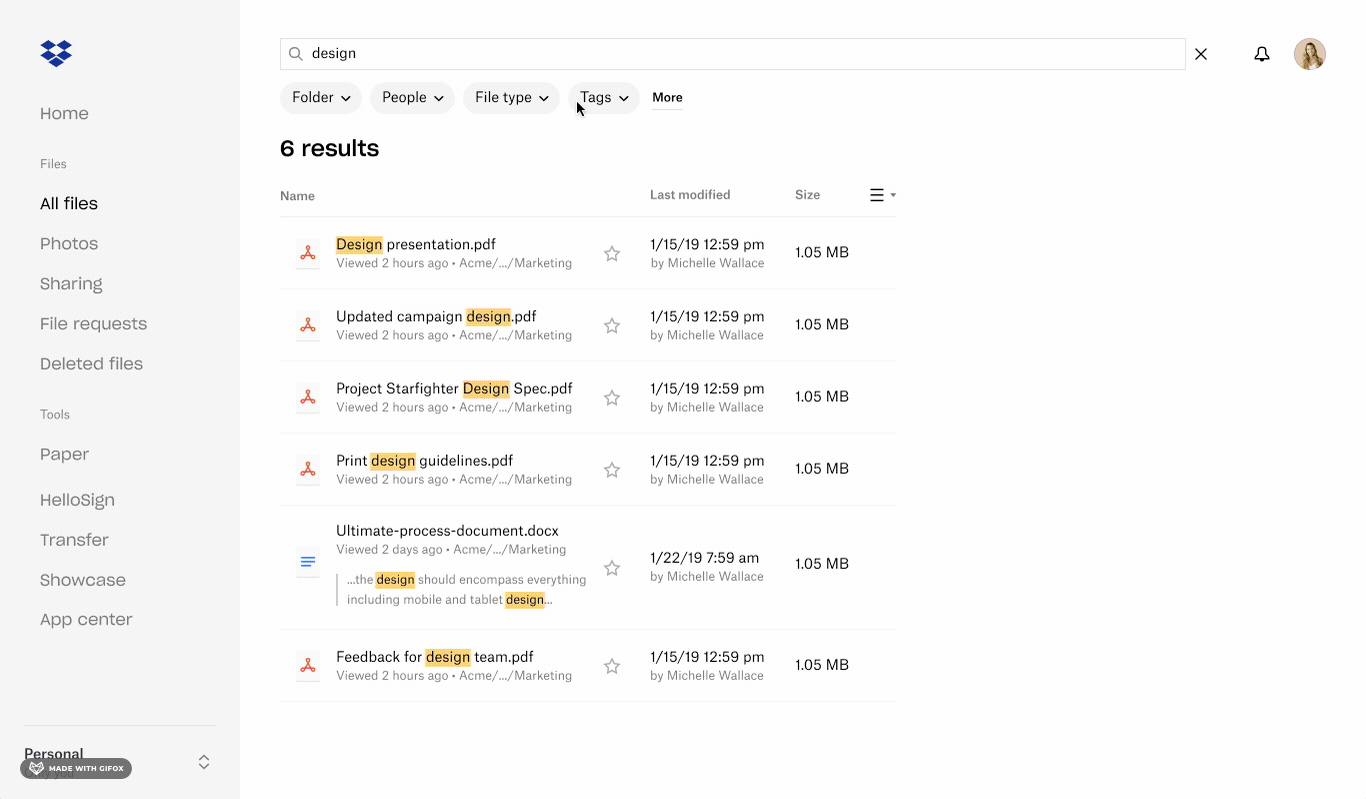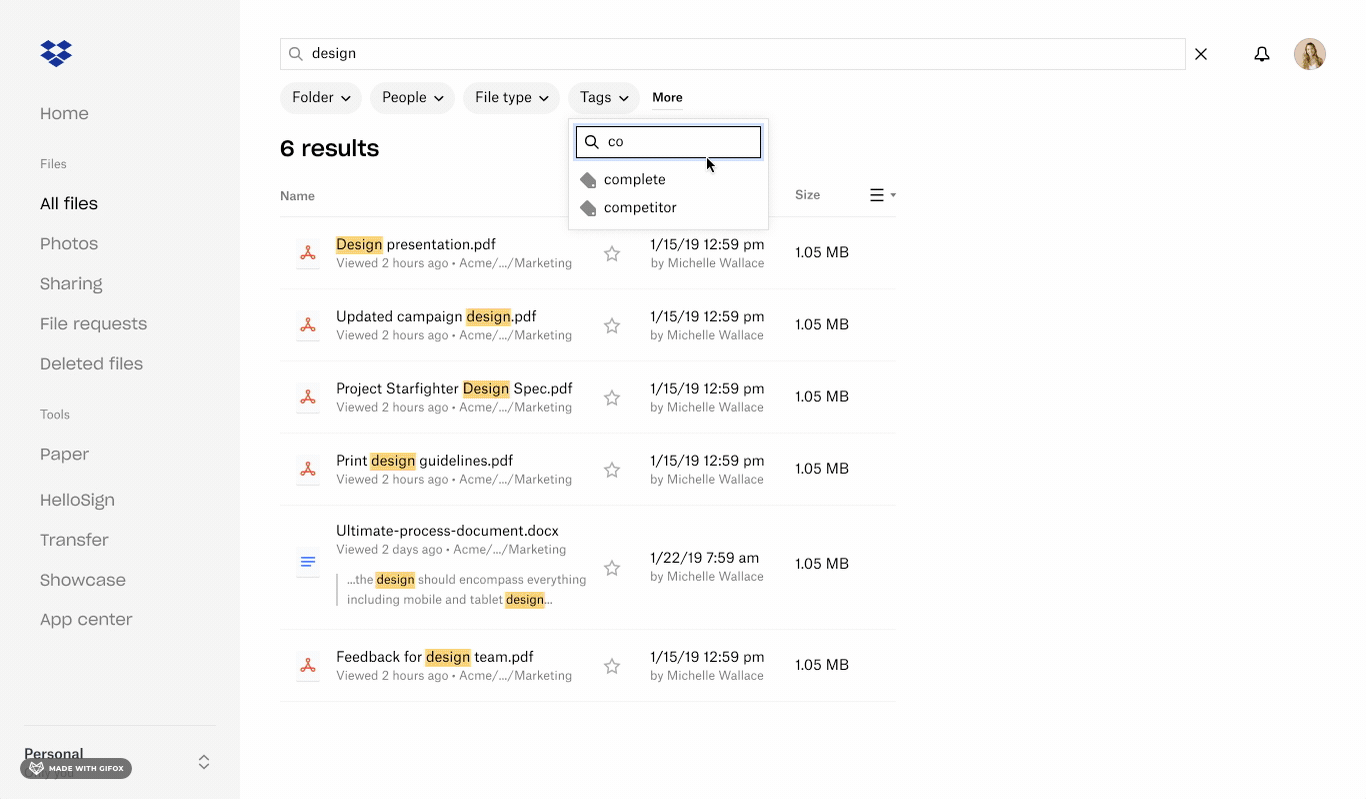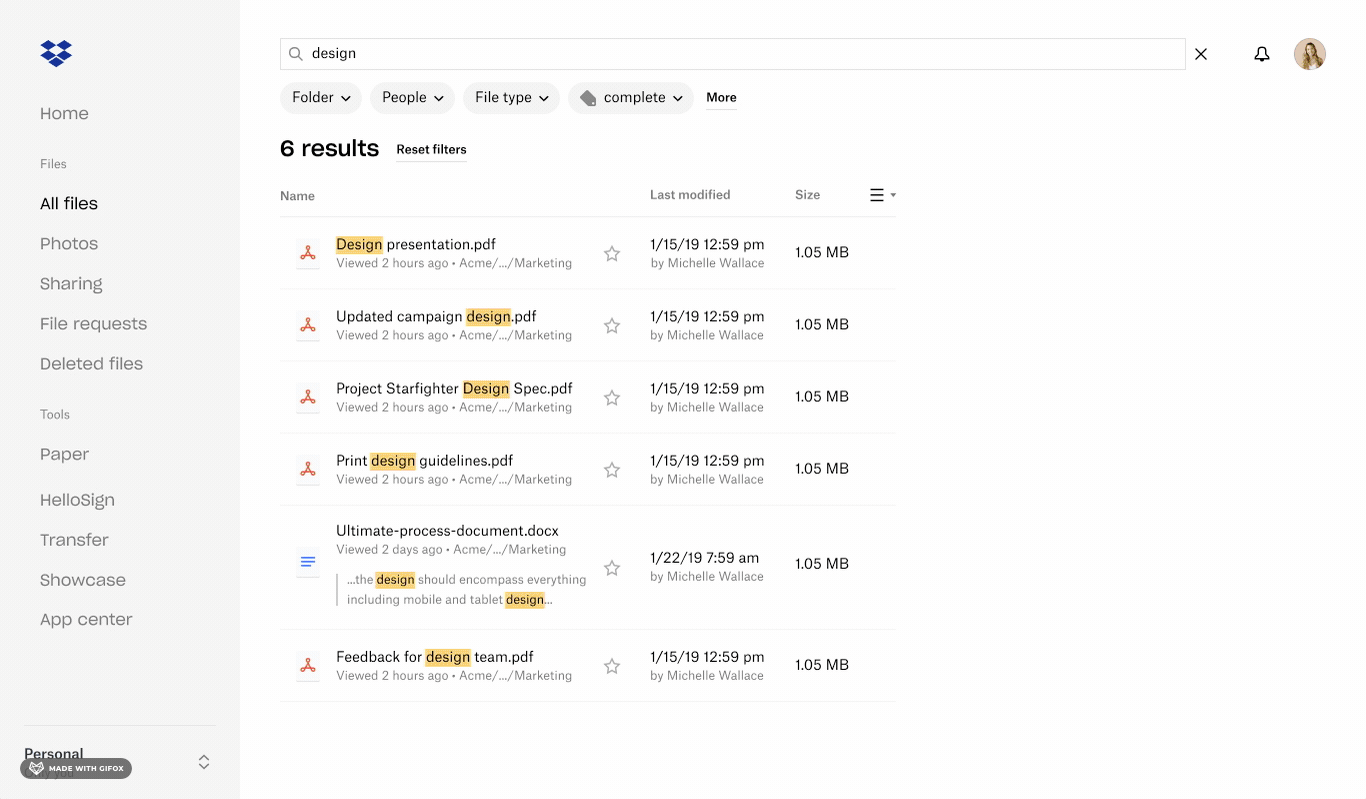
Searching for content and applying filters for tags
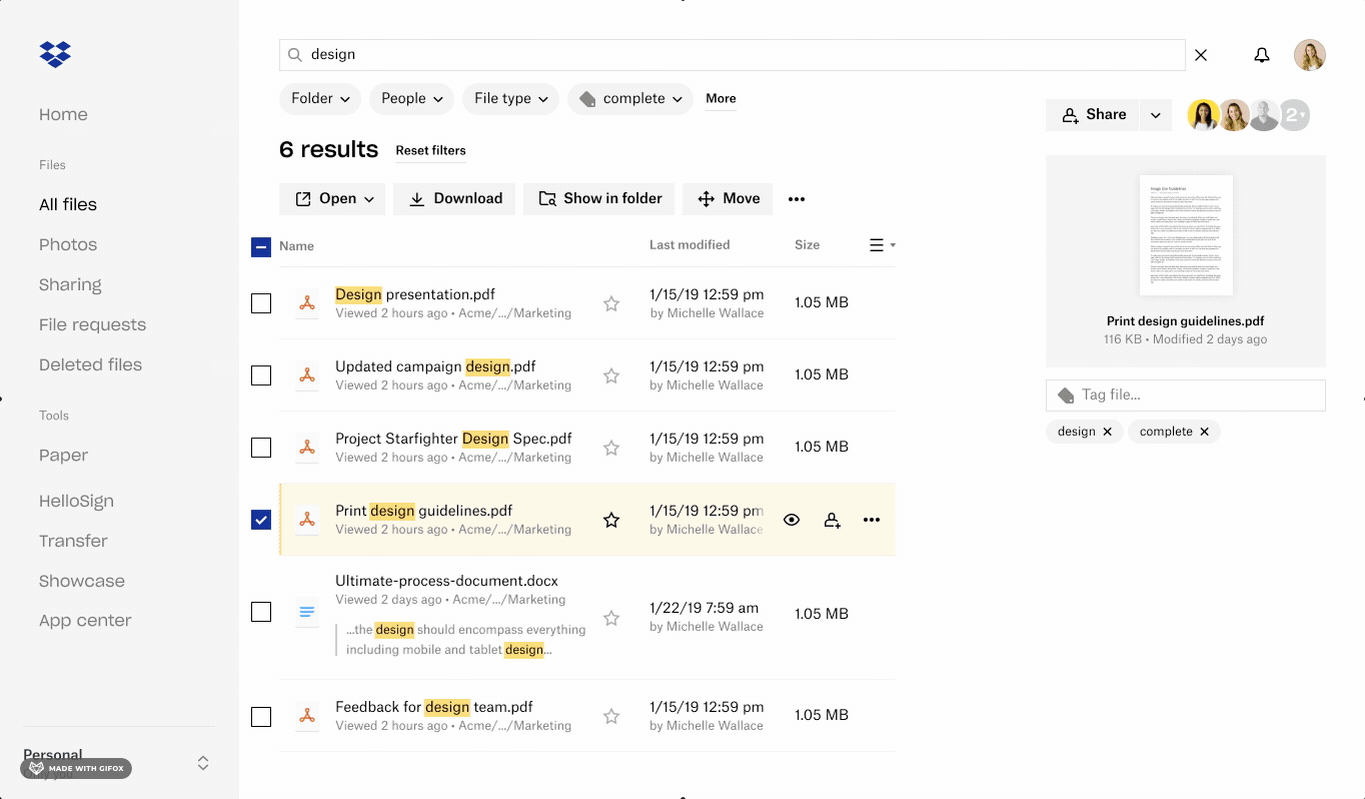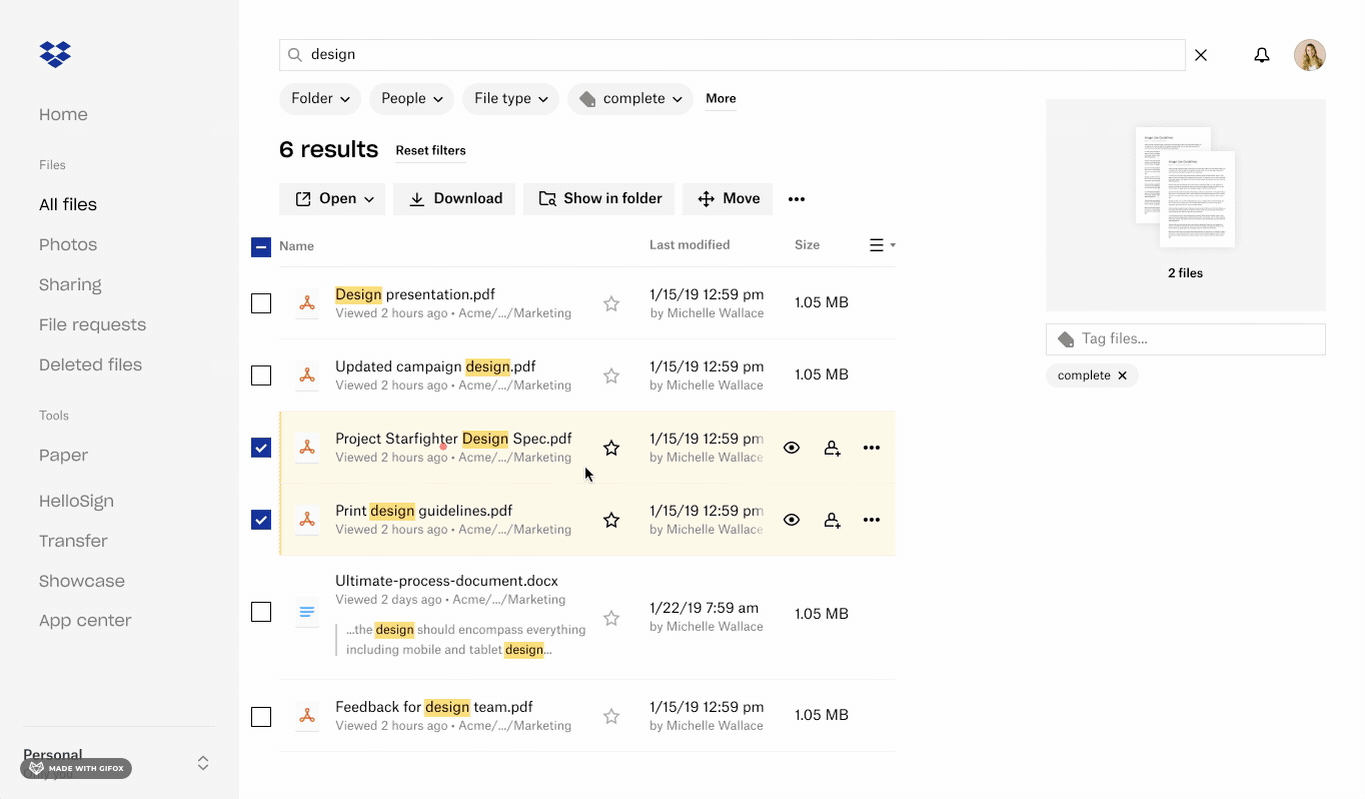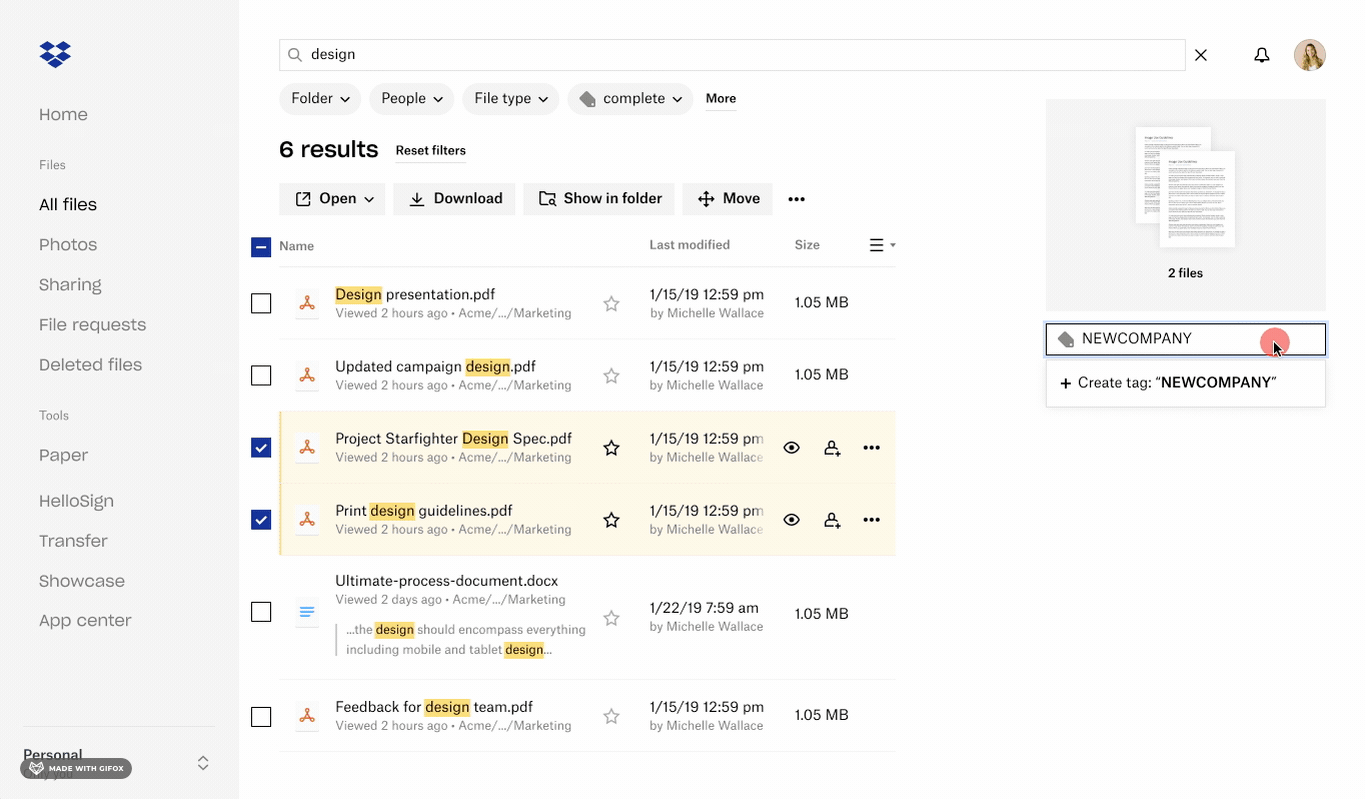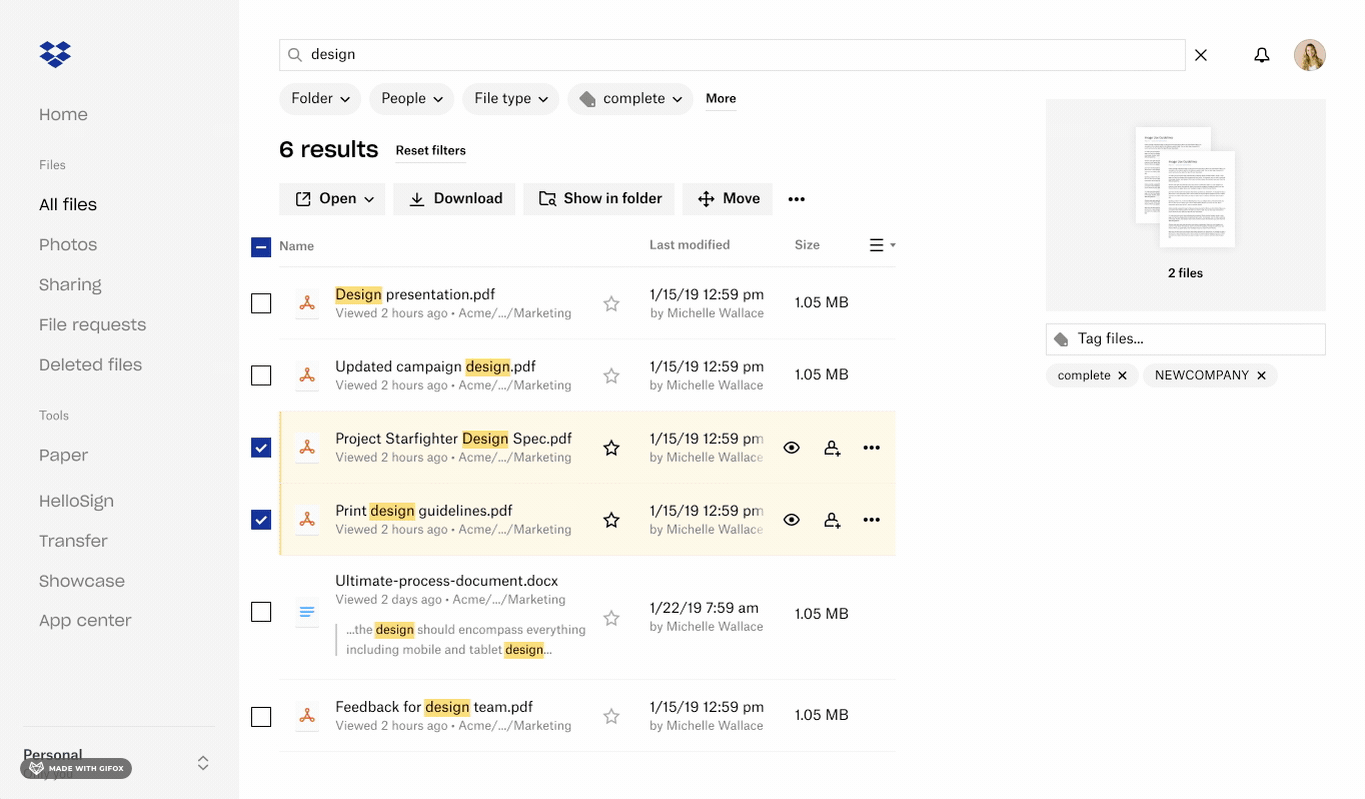
Selecting items and applying tags to selected content
What I learned
Bringing engineering into the design process earlier (not just for feasibility checks, but as collaborators on the problem) shortened cycles and built the kind of trust that makes cross-functional work faster. The simplest MVP produced the most useful signal: how users actually named things told us more than any prior research about how to build the next layer.
Hey, there’s still more to see ↓
Dropbox Search Operators
Reducing time-to-success in Dropbox search for millions of daily active users
title:finalfinalfinal
Return to Home
Dropbox Metadata
The smallest MVP that could answer the biggest retrieval question
The problem
By 2020, "I know it's in here, I just can't find it" was one of Dropbox's most consistent enterprise complaints. Folder hierarchies didn't scale with team growth, naming conventions broke down across collaborators, and without shared language, retrieval failed. Often, this sort of breakdown occurred at the moment it mattered most.
The strategic context
Competitors had classification and tagging systems. The obvious move was feature parity. I pushed to reframe the opportunity: rather than replicating what existed elsewhere, we could let users define their own taxonomy. Teams already had unofficial organizational language. The question was whether we could surface it.
My role
I led design on the metadata MVP, working alongside a researcher, PM, and eng partners across web and desktop. I owned the design direction, scoped the MVP, and worked directly with the design systems team to ensure tagging patterns extended existing components rather than introducing one-off interactions.
What made this hard
Tagging is high-frequency and repetitive, and any friction in the interaction leads to abandonment. There were no existing tagging patterns in Dropbox's design system, so I had to solve for the interaction and the system simultaneously. I also had to balance discoverability for new users against speed for power users who might tag hundreds of files.
How should tags appear in search?
- Tags needed to be visible in both the search bar and results list.
- We had to make this work without breaking existing search interactions, so working closely with eng was critical.
What’s the most efficient and identifiable way to add a tag?
Tagging is repetitive. A clunky interaction would mean abandonment. We explored multiple approaches to balance:
- Easy discoverability for new users.
- Low-friction speed for power users who tag regularly.
How should tagging fit into the design system?
There were no existing patterns for tagging in Dropbox. To avoid introducing one-off interactions, I worked with the design systems team to evolve existing patterns so tagging felt native across web and desktop.
The solution
I scoped the MVP to two core scenarios: applying tags to files and folders (in bulk and individually), and surfacing tags in search queries and results. This gave us enough surface area to measure real behavior while keeping scope tight enough to ship and learn. The foundation was intentionally minimal, designed in a way to inform the next layer of investment in smart collections, automated tagging, and rules-based views.
Searching for content and applying filters for tags
Selecting items and applying tags to selected content
What I learned
Bringing engineering into the design process earlier (not just for feasibility checks, but as collaborators on the problem) shortened cycles and built the kind of trust that makes cross-functional work faster. The simplest MVP produced the most useful signal: how users actually named things told us more than any prior research about how to build the next layer.
Hey, there’s still more to see ↓
title:finalfinalfinal
Dropbox Search Operators
“I know it’s here, but I still can’t find it”